Day two of the PASS Summit brought Dave and me a brilliant and powerful keynote about Azure Cosmos DB, high quality deep dive sessions about Azure SQL Data Warehouse and Azure Data Lake, and again, it provided us opportunities to connect to the Microsoft product teams.
Day Two Keynote: Globally distributed databases made “simple” by Rimma Nehme
Today’s keynote was all about Microsoft’s latest addition to the data platform: Azure Cosmos DB. This service was designed for the cloud with the requirements that it should offer turnkey global distribution, guaranteed low latency at the 99 percentile worldwide, guaranteed high availability and consistency and elasticity when it comes to scaling storage and throughput while operating at low cost.
As Cosmos DB is designed for global distribution and usage it is often used by globally operating companies, for example an airline that operates at airports all over the world. Another nice example is the database behind the Azure portal, it is Cosmos DB too!
Data in Cosmos DB is distributed globally but reads and writes are served from local the region to offer the best performance. There is a guaranteed milliseconds-range latency worldwide for replication to the other regions. All data is indexed by default on SSD storage to make sure reads are always very fast.
Cosmos DB offers different types of data storage; key-value, column family, document (former Document DB) and graph. Under the hood however, there is only one (type of) data storage! This makes it possible for developers to switch over to other data storage types easily. This is required as apps evolve over time and schemas change. That’s also why the object model was designed to be schema-free and schema-agnostic. The API layer on top of the data stores makes sure no recompilation is needed when you migrate your existing database to Cosmos DB. This makes lifting and shifting on-premises databases a lot easier.
Adding regions are a click away, Cosmos DB offers turn-key global distribution. If a regional data center outage occurs, Cosmos DB will failover to a prioritized list of secondary regions. It is possible to elastically provision resources on demand and when you don’t need them anymore you can scale them down. You can easily scale from 10 to 100s of millions of transactions/sec across multiple regions. Cosmos DB is designed to independently scale storage and throughput. This happens completely transparent within the regions as needed, for example a region can scale down at night while another region scales up because it is daytime there.
Relational databases usually offer strong consistency while NoSQL databases often use eventual consistency. In general, strong consistency comes with high latency while eventual consistency comes with latency. The tradeoff is between consistency, availability and latency. With Cosmos DB this tradeoff can be monetized. 5 consistency models with clear differences can be used: Strong, Bounded-stateless, Session, Consistent prefix, and Eventual.

How to impress at parties? Talk about the 5 consistency models in Azure Cosmos DB!
Data stored in Cosmos DB is highly available by design. Backups are not required from a disaster recovery perspective because of the geo replicas. You can make backups but they are for scenarios in which you, for example, accidently deleted data locally. If you don’t want to have your data replicated worldwide you can geo-fence data, for example to keep it in Europe.
RUs are the bitcoins of the Cosmos DB world. It is a combination of % memory, % CPU and % IOPS. If you exceed your RU budget, you will get throttled. In the background Machine Learning models are used on telemetry data to decide actual costs and how many RU’s are needed to run your queries.
Dining on data: consume and query petabytes of data with Azure SQL Data Warehouse by James Rowland-Jones
Azure SQL Data Warehouse is optimized for elasticity which makes it possible to scale on demand. The fundamental difference with SQL Database is the fact that compute and storage are separated. Data is spread over 60 databases by default. All these databases contain row and columnstore data storage possibilities.
Key is the partitioning strategy which should be optimized to distribute the data over the storage nodes in the best possible way to optimize performance.
The new compute optimized performance tier which is in preview this fall is optimized for compute as a storage, cache is added to the compute nodes to keep data in memory. Columnstore tables are added to this new cache while rowstore tables remain on the remote storage. Compute performance tier starts at 1000 cDWUs, the elasticity tier starts at 100 DWUs. Every time you pause your SQLDW, your cached data is lost.
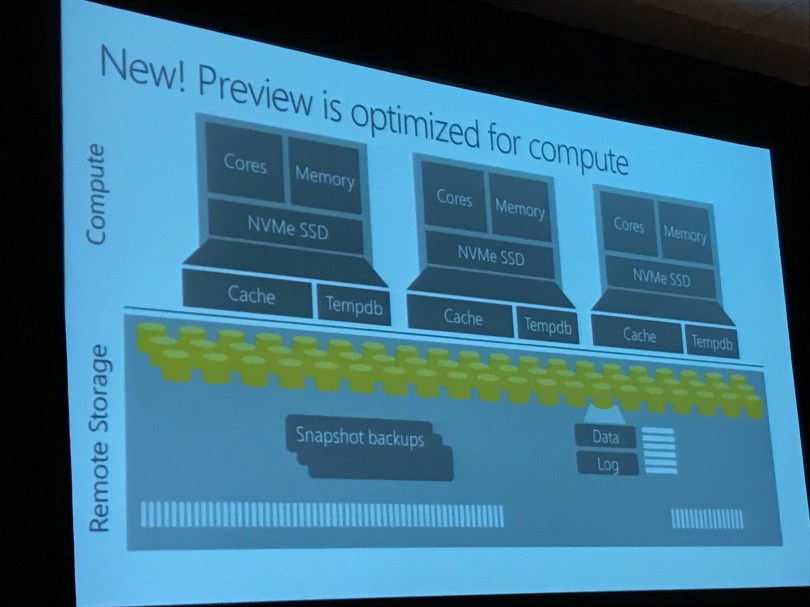
A new feature is the Aggressive Tuple Mover which converts closed row groups into columnstore row groups, improving the quality of the columnstore automatically in the background.
Modernizing ETL with Azure Data Lake: Hyperscale, multi-format, multi-platform, and intelligent by Michael Rys
The Data Lake approach is to ingest the data in a format that is as close to the original format as possible so you don’t lose anything. Ingest everything, analyze later. Modern Data Warehouse architectures that include a Data Lake move from ETL to LETS patterns (Load Extract Transform Store), schematizing the unstructured data for analysis.
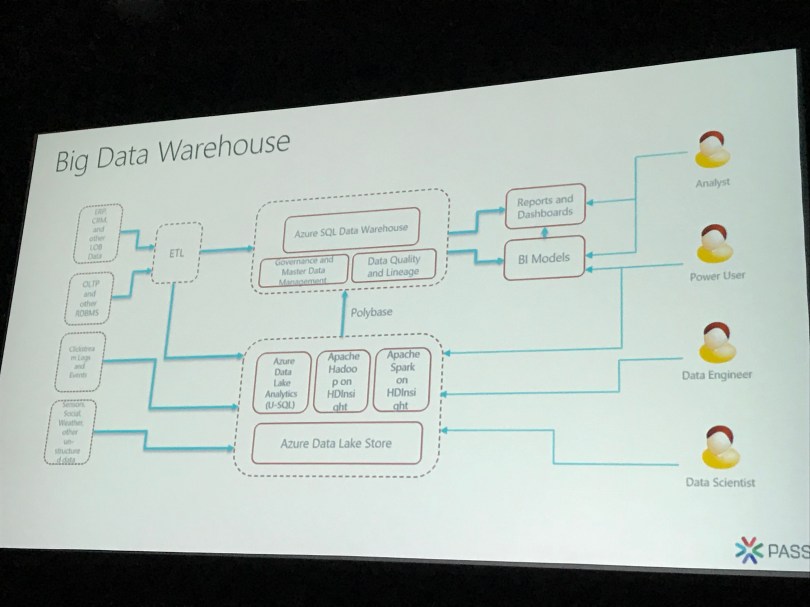

Azure Data Lake Analytics (ADLA) workloads are batch oriented and ideal for analytics and data science, using U-SQL, .NET, R and Python on very large amounts of unstructured data. U-SQL is a new query language which is familiar to SQL developers, making querying big data accessible for millions of people. Using ADLA you can query data where it lives with distributed queries to Azure SQL Data Warehouse, Azure SQL Database, SQL Server on Azure VMs and Azure Blob Storage.
ADLA has 6 built-in cognitive functions: Face API, Image Tagging, Emotion Analysis, OCR, Text Key Phrase, Extraction, Text Sentiment Analysis. You will not get billed extra on top of your ADLA usage to make use of these functions!
Azure Data Factory can be used to orchestrate ADLA jobs and to ingest data into ADLS. ADF v2 now adds support for ADLA pipeline and recurring job insights. This gives you the ability to analyze the ADLA jobs that are executed from ADF pipelines from the Azure portal (at the ADLA side).
Extracting and outputting Parquet files is soon supported using U-SQL. The public preview for this functionality starts this month. Parquet files are in columnar format and currently often used with Spark using Spark-SQL.
Limits on number of files and file sizes can be improved with the FileSetV2Dot5:on feature preview.
The Azure SQL Data Warehouse team is working on distributed queries to Azure Data Lake Catalog tables. This functionality is planned for somewhere next year.
Focus Group session Azure-SSIS & ADF
Last but not least was another focus group session in which we gave feedback to the Azure SSIS & ADF product team. This session was led by Jimmy Wong and Janine Zhang. At Macaw we are always investing in the latest technology and that’s why we have been in contact with Jimmy for quite a while, so it was very nice to finally meet him in person. After the Focus Group session we went for some coffee to discuss the Macaw Cloud Lifter program in which we make it possible to lift and shift entire on-premises SQL Server based BI solutions to the Azure PaaS cloud. We have talked about the way forward and how we can help each other in the coming months. We are very much looking forward to the first results. If your company is interested in a lift and shift to Azure make sure to contact us!

